Course Project • Highlights
Speech Synthesis From Silent rtMRI Videos | CPSC 533R Course Project
In this course project, the objective was to reconstruct and synthesize speech sounds from real-time magnetic resonance imaging (rtMRI) videos that capture articulatory movements during speech production.
We used the USC-TIMIT rtMRI speech production dataset, which contains synchronized video and audio data. (Link: https://sail.usc.edu/span/usc-timit/)
We preprocessed the videos using Eulerian video magnification and reduced the audio noise.
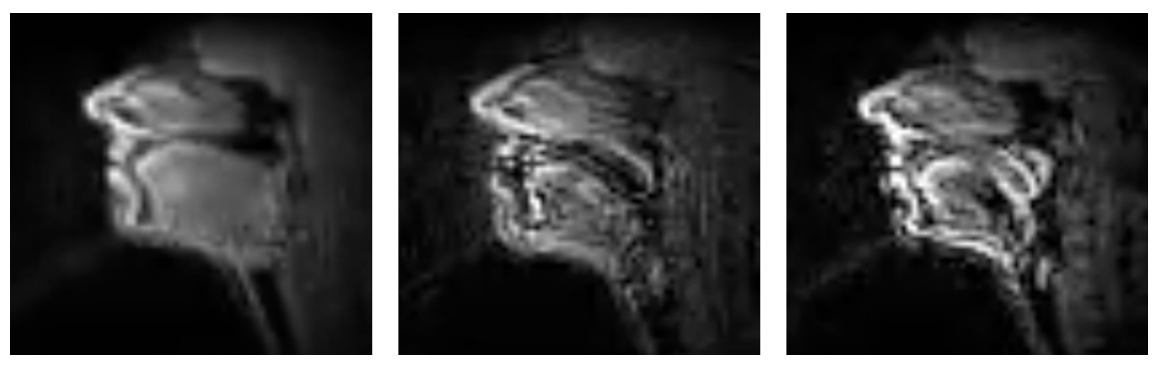
We developed a ResNet-based model that consist of 2D spatial and 1D temporal convolutional layers to predict the mel-cepstrum coefficients, then applied mel-log spectrum approximation filters to synthesize the resulting speech.