Speech Onset Detection Using sEEG | HCT Side Research Project
Overview
This project focused on detecting speech onset from stereotactic EEG (sEEG) signals using deep learning, with applications in brain–computer interfaces (BCIs) and assistive communication for individuals with speaking disabilities.
Using intracranial neural recordings from patients speaking prompted words, we framed speech onset detection as a binary classification problem and compared classical machine learning approaches with deep learning models. Part of this project was completed as coursework for CPSC 554X. The data was obtained from a public clinical dataset.
Problem & Context
Speech-based BCIs often aim to reconstruct speech directly from neural activity, but this is challenging due to high dimensionality and limited data. Speech onset detection offers a simpler and more robust alternative: detecting intent to speak rather than reconstructing full audio.
Key challenges included:
- High variability in sEEG electrode placement across patients
- Limited dataset size and strong subject-specific effects
- No ground-truth speech onset annotations in the raw dataset
- Strong class imbalance between speech and non-speech windows
Data & Feature Engineering
We used a public dataset containing sEEG recordings and synchronized audio from 10 patients speaking prompted Dutch words.
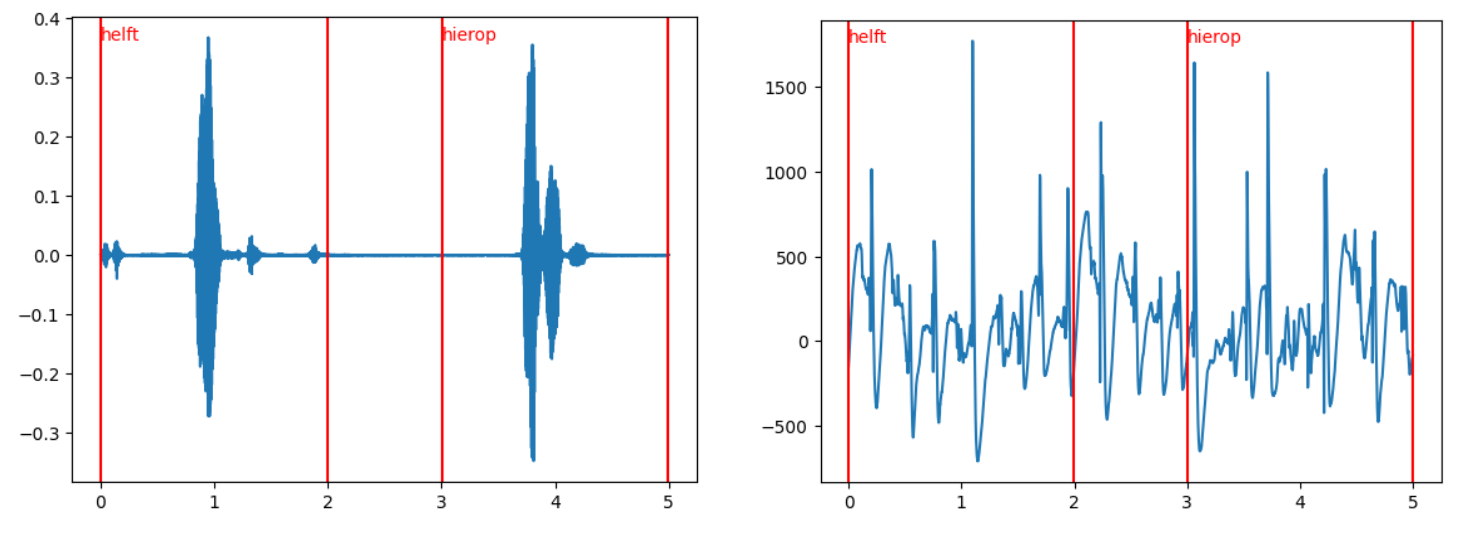
Speech Onset Labeling
- Audio recordings were manually processed to identify speech onset timestamps
- Automatic onset detection was unreliable due to movement noise
- Final labels were derived through a combination of signal processing heuristics and manual correction
Neural Feature Extraction
- sEEG signals were bandpass filtered and transformed into frequency-domain features
- Power was extracted from standard EEG bands (theta, alpha, beta, gamma)
- To address variability in electrode placement, channels were clustered using spatial similarity via Bisecting K-Means, producing consistent multi-channel inputs across patients
Modeling Approach
We evaluated both classical and deep learning models:
Baselines
- Random Forest classifier using frequency-band power features
- Provided a strong but limited baseline (AUC ≈ 0.67)
Deep Learning Models
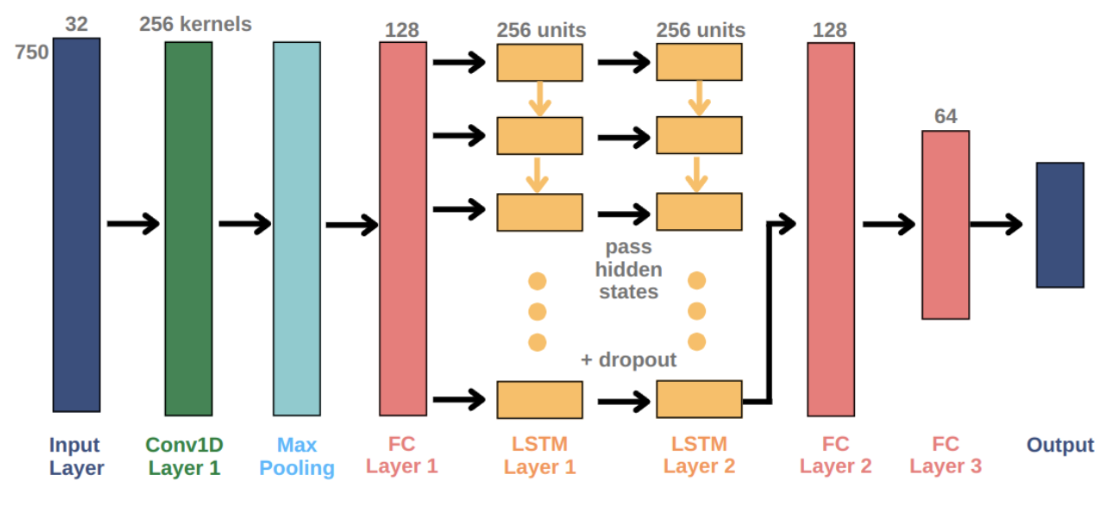
- GRU and LSTM models operating on raw multi-channel sEEG windows
- A CNN–LSTM architecture, using convolutional layers for spatial feature extraction and LSTM layers for temporal modeling
The CNN–LSTM model proved most effective at capturing spatiotemporal structure in neural signals.
Evaluation & Results
Models were evaluated using ROC curves and Area Under the Curve (AUC) as the primary metric, with additional analysis using precision, recall, and F1-score.
Key results:
- CNN–LSTM achieved an AUC of 0.89, outperforming classical baselines and recurrent-only models
- Hybrid models combining handcrafted features with recurrent networks improved performance over pure RNNs but did not surpass CNN–LSTM
- Temporal modeling was critical for accurate onset detection
- Overfitting and limited generalizability across participants remained key challenges
My Role
- Implemented frequency-domain feature extraction from sEEG signals
- Developed and evaluated classical ML and deep learning models
- Designed channel clustering strategy to address cross-subject variability
- Conducted model evaluation and comparative analysis
- Co-authored the final project report
Project completed collaboratively as part of a course team.