Speech Synthesis From Silent rtMRI Videos | HCT Side Research Project
Overview
This project investigated speech synthesis from silent real-time MRI (rtMRI) videos by learning a mapping from articulatory motion to acoustic representations. The goal was to reconstruct intelligible speech using only visual information of the vocal tract, integrating methods from computer vision, speech processing, and machine learning.
A portion of this work was completed as part of the CPSC 533R course project. We used the USC-TIMIT rtMRI speech production dataset, which captures synchronized vocal tract motion and audio recordings.
Problem & Challenges
Reconstructing speech from articulatory motion is challenging due to:
- Subtle and rapidly changing vocal tract movements
- Limited spatial and temporal resolution of rtMRI videos
- Weakly understood articulatory-to-acoustic mappings
- MRI-induced noise in recorded audio
- Silent and unvoiced regions that complicate learning
Additionally, many video-to-speech models are designed for lip-reading from facial videos, which differ substantially from rtMRI data in appearance, dynamics, and noise characteristics.
Approach
Rather than treating this as a purely learning problem, we explored design choices across multiple layers of the pipeline.
Visual Representation
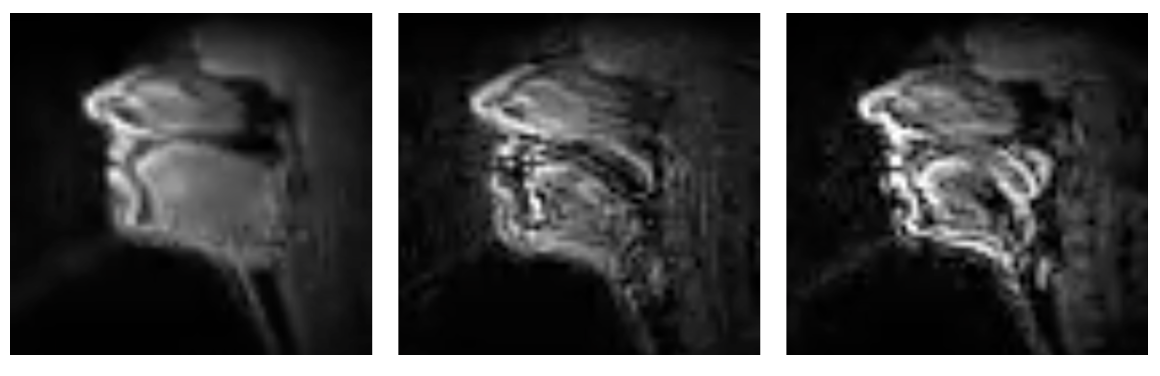
- Used short sequences of grayscale rtMRI frames to capture articulatory motion over time
- Experimented with video motion magnification (Eulerian and phase-based) to amplify subtle movements
- Evaluated when visual enhancement helped versus when it amplified noise
Acoustic Representation
To bridge visual motion and sound, we compared several intermediate speech encodings:
- Linear Predictive Coding (LPC) coefficients
- Mel-cepstrum analysis coefficients
- Mel-scaled spectrogram vectors
Mel-cepstrum coefficients were ultimately more robust, offering a better balance between perceptual relevance and learnability.
Learning Architecture
- Began with a VGG-style CNN adapted from prior lip-reading work
- Transitioned to a ResNet 2D + 1D architecture, explicitly separating spatial and temporal processing
- This design better captured the temporal structure inherent in speech production
Evaluation & Results
The final pipeline combined:
- ResNet 2D + 1D modeling
- Mel-cepstrum speech encoding
- An 80/20 train–test split on USC-TIMIT data
We evaluated performance using:
- Normalized Mean Absolute Error (NMAE) on predicted speech features
- Mel-Cepstral Distortion (MCD) to assess reconstructed speech quality
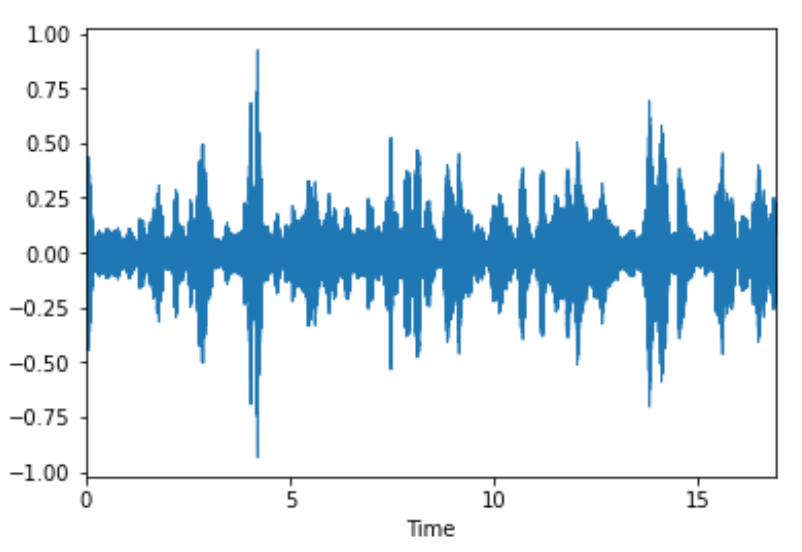
Results showed that the system could reconstruct speech with recognizable temporal and spectral structure. While fine-grained spectral detail remained difficult to recover, the synthesized audio demonstrated meaningful correspondence to the underlying articulatory motion.
Here is a sample of the resulting speech reconstructed by our model as well as a visual representation of the audio waveform:
Ablation studies highlighted that:
- Temporal modeling was essential for intelligible synthesis
- LPC struggled with silence and volume prediction
- Motion magnification techniques amplified MRI noise and were not well suited for this dataset
My Role
- Led video and audio preprocessing, including noise reduction, segmentation, and motion enhancement experiments
- Designed and executed ablation studies to evaluate preprocessing and representation choices
- Implemented and evaluated CNN- and ResNet-based models
- Analyzed results using objective speech quality metrics (NMAE, MCD)
- Co-authored the final project report
Project completed collaboratively; responsibilities were shared across research, implementation, and analysis.